




Data labeling, in terms of machine learning, is the process of identifying and marking data samples. The labeling process is often manual but is usually performed or supported by the software.
Most machine learning models use supervised learning. An algorithm is applied to map an input to an output. For machine learning to work, you need a labeled data set so that the model can learn from it in order to make the right decisions. Typically, in data labeling, humans are asked to make judgments about specific unlabeled data. For example, labelers are asked to tag all the images in a dataset where “the photo contains an animal” is true. The marking can be as simple as yes/no or as detailed as identifying the dimensions of the pixels in the image associated with the animal. Machine learning uses human-supplied tags to learn the patterns, and the process is known as “model training”. These results from the trained model are also used as predictions for the new data sets.
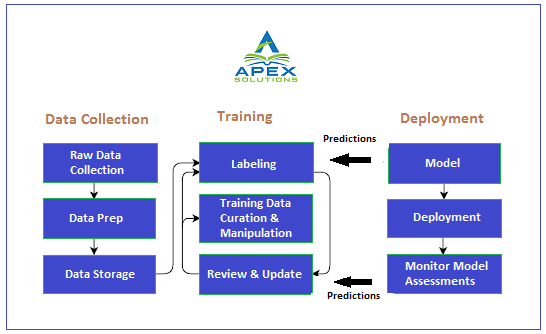
How does Data Labeling work?
In the machine learning process, a precisely labeled set of data is used as an objective standard for training, and evaluating a particular model is often referred to as “Ground truth”. The accuracy of your trained model completely depends on the accuracy of your ground truth. It is therefore imperative to invest time and resources to ensure high-precision data labeling.
About Labeled Data And Ground Truth
What is labeled data?
In the machine learning process, If you have labeled data, this means your data is marked up or annotated to get the desired result, and the same way you want your machine learning model to predict the result. In general, data labeling can be referred to as tasks that involve data marking, annotation, classification, moderation, transcription, or data processing.
What is data annotation?
Data annotation generally refers to the process of data labeling. Data annotation and data labeling are often used synonymously, although they can be used differently depending on the industry or use case. The tagged data highlights the characteristics of the data or properties, features, or classifications that can be analyzed for patterns that help predict the target. For example, in the computer vision of autonomous vehicles, a data tagger can use frame-by-frame video tagging tools to show the location of road signs, pedestrians, or other vehicles.
What is ‘Human-in-the-Loop’ (HITL)?
HITL refers to humans in the loop and it leverages both human and machine intelligence to build machine learning models. In a HITL configuration, people are deeply involved in a virtuous circle of improvement where human judgment is used to train, tune, and test a particular data model.
What are the labels in machine learning?
Human in the loop uses to identify and call out the features present in the data and are referred to as labels. Choosing informative, discriminatory, and independent characteristics for labeling is critical if you want to develop high-performance algorithms for pattern recognition. Classification and regression: Precisely labeled data can provide ground truth for testing and iterating your models.
What is a “ground truth” in machine learning?
In machine learning, “Ground Truth” means checking the accuracy of the results of machine learning algorithms with the real world. In essence, it is a reality check for the algorithm’s accuracy. The term is borrowed from meteorology, where “ground truth” refers to information obtained on the ground where a meteorological event actually occurring, and this data is then compared with predictive forecast models to determine its accuracy.
What is “training data” in machine learning?
Training data is the collection of labeled data you use to build a machine learning model or algorithm.
Data labeling – Essential Tasks
- Using a tool to enrich data.
- Quality assurance for data labeling.
- Process iteration, such as changes in data feature selection, task progression, or Quality Assurance.
- Management of data labelers.
- Training of new team members.
- Project planning, process operationalization, and measurement of success.
5 essentials to data labeling
- Data Quality And Accuracy – We’ve learned that accuracy and quality are two different things.
- Scale – Capacity to scale your workforce up or down.
- Pricing – The model a data labeling service uses to calculate pricing can have implications for your overall cost and for your data quality.
- Security – A data labeling service should comply with regulatory or other requirements, based on the level of security your data requires.
- Tools – which you will need whether you choose to build it yourself or to buy it from a third party.
Data labeling services and Data Annotation services

Pros and Cons of Labeling approaches
| Approach | Description | Pros | Cons |
| Internal Labeling | Assignment of tasks to an in house data science team | > Predictable result | > It takes much time |
| > High accuracy of labeled data | |||
| > Ability to track progress | |||
| Outsourcing | Recruitment of temporary employees on freelance platform, posting vacancies on social media and job search sites | > Ability to evaluate applicants skills | > Need to organize work flow |
| Crowd Sourcing | Cooperation from freelancers from crowdsourcing platforms | > Cost Saving | > Poor quality of work |
| > Fast results | |||
| Specialized Outsourcing companies | Hiring an external team for a specific project | > Assured quality | > Higher price compare to crowdsourcing |
| Synthetic labeling | Generating data with the same attributes of real data | > Fewer constraint for using sensitive and regulated data | > High computational power required |
| > Training data without mismatches and gaps | |||
| > Cost and time effectiveness | |||
| Data Programming | Using scripts that programitacally label data to avoid manual work | > Automation | > Lower quality dataset |
| > Fast Results |







